RAG Prologue
Let’s Use RAG Like This
Since the public release of ChatGPT on November 30, 2022, large language models (LLMs) have driven revolutionary advancements in artificial intelligence, gaining attention across various industries. LLMs are models trained on vast amounts of text data, enabling them to understand and generate human-like language. These models are widely applied in tasks such as natural language processing, translation, and text summarization. In 2023, we witnessed the development of various LLMs, including OpenAI’s GPT-4, Google’s BERT, and Meta’s LLaMA. Each of these models has continued to evolve, leveraging unique features and strengths. Notably, Meta’s LLaMA series offers versions with 7 billion, 13 billion, and 70 billion parameters, showcasing exceptional performance in diverse natural language processing tasks. The advancements in LLMs have brought about transformative changes in areas such as customer service, content creation, and education. Through this tutorial, I aim to share the knowledge and insights I have gained. I will cover topics such as using publicly available models on Hugging Face, performing LLM inference with Ollama, applying various techniques with LangChain, and exploring AI agents and LangGraph. Please stay tuned and join me on this journey!
Recommended For:
This tutorial is perfect for those who relate to any of the following scenarios (and, to be honest, all of these apply to me!):
- Your company has restricted the use of ChatGPT due to security concerns.
- You want to run an LLM on your own computer but don’t know how to get started.
- You feel that ChatGPT gives irrelevant or nonsensical answers to slightly more technical questions, and you’re wondering if this can be improved.
- You want to build a dataset tailored to your domain and create your own version of ChatGPT.
- You’d like to share a ChatGPT model infused with your domain knowledge with others.
Limitations of LLMs: Hallucination
LLMs rely heavily on the data they are trained on, which means they can generate inaccurate information due to biased or insufficient training data or model overfitting.
Additionally, they often struggle to provide accurate answers for information that has not been included in their training, such as recent or unlearned updates.
This phenomenon is referred to as “hallucination”.
While the output may seem creative, it is important to remember that LLMs are ultimately systems driven by instructions and probabilities.
Overcoming the Limitations of LLMs: RAG
To address the limitations of LLMs, various approaches have been proposed.
One such approach is fine-tuning, which involves further training a pre-trained model on data from a specific domain (e.g., medical, legal, financial) to optimize the model.
This allows the model to acquire domain-specific expertise and provide accurate, specialized responses. However, fine-tuning requires significant time and resources, and it may reduce the model’s general applicability.
In contrast, RAG (Retrieval-Augmented Generation) offers a way to maintain the model’s generality and adaptability while generating accurate and reliable answers.
RAG connects LLMs to external knowledge sources, allowing the model to overcome its limitations while leveraging its strengths. The concept of RAG is to provide the LLM with a “cheat sheet” when it encounters unfamiliar questions (e.g., questions involving the latest knowledge or untrained information). The model then uses this cheat sheet to generate informed and accurate responses.
RAG stands out as a promising approach for addressing the challenges of LLMs while retaining their advantages.
Sequence of LLMs Using RAG
User Query Input
The user inputs a question or query.Data Retrieval and Segmentation for the Cheating Sheet
Relevant data is gathered and segmented from sources such as web searches or documents (e.g., PDF, HTML).Data Embedding and Storage in a Vector Database
Data is embedded into vector representations and stored in a vector database.Text Embedding of the Query
The query is transformed into an embedding vector.Similarity-Based Retrieval via Retriever
The retriever searches the vector database for data most similar to the query(e.g., cosine similarity).Prompt Context Construction
Contexts for the prompt are created using the retrieved data.Response Generation by the LLM
The LLM generates an answer based on the constructed prompt contexts.
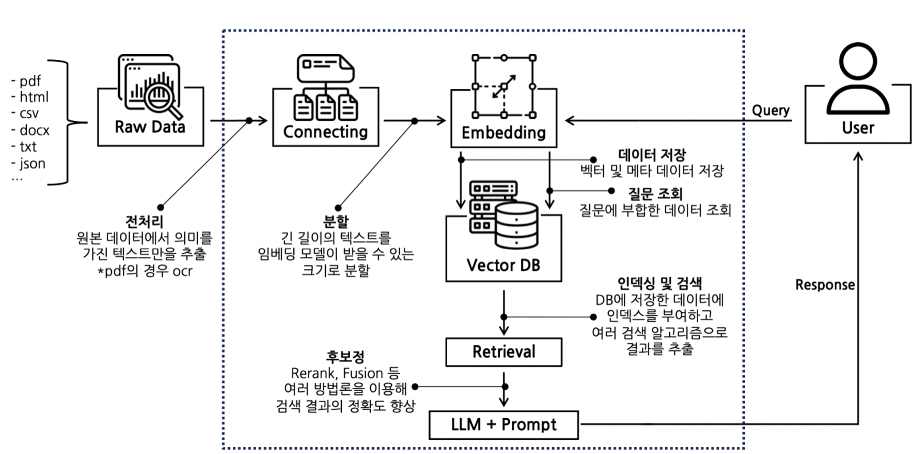 RAG Intro(Source: NAVER CLOUD PLATFORM)
RAG Intro(Source: NAVER CLOUD PLATFORM)