Setup Ollama on a server.
Let's run Ollama Container on a server.
We have installed Ollama on both Windows and Ubuntu (WSL). However, if we want to provide an LLM service, Ollama needs to run on a server. To do that, we will likely need to run a Docker container in a Kubernetes (k8s) environment. (There’s also the old-fashioned way of installing it directly on bare metal.)
I’ll write this post taking several scenarios into consideration.
- (Case 1) Let’s pull the Ollama image and run the container on a specific server.
- (Case 2) Automatically load a pre-specified LLM model when running the Ollama container on a specific server.
- (Case 3) Automatically load a pre-specified LLM model when running the Ollama container on a specific isolated (air-gapped) server.
Confirmed that the Ollama image exists on Docker Hub
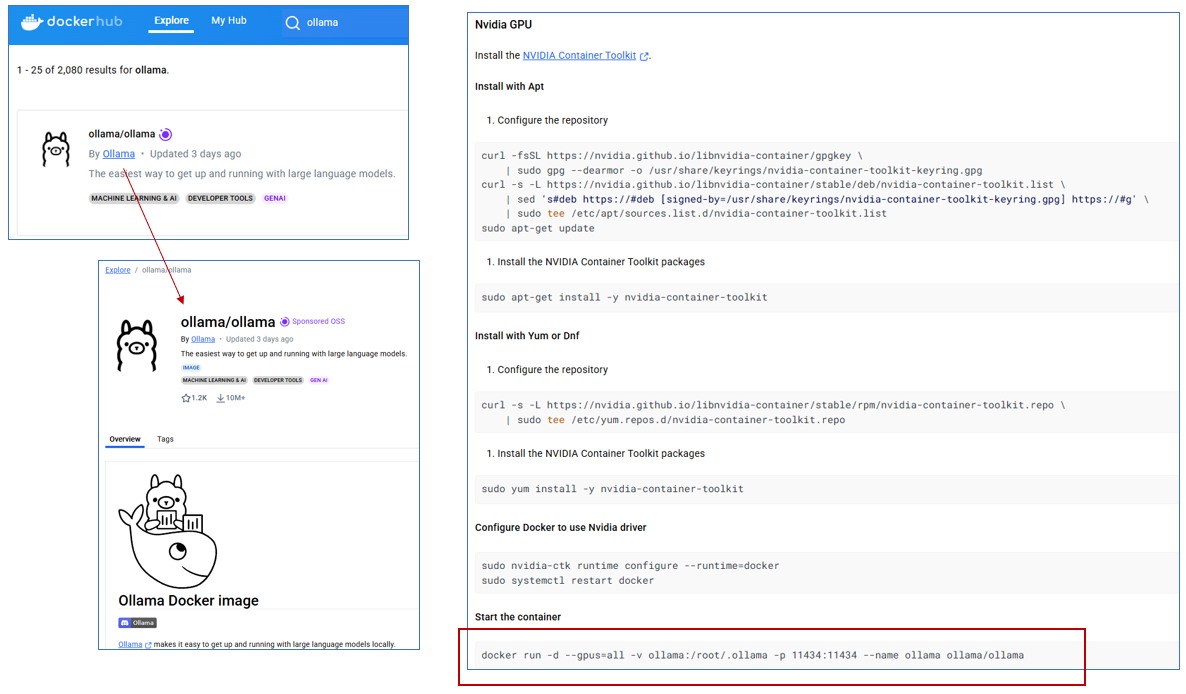 Ollama on Dockerhub(Source: Dockerhub)
Ollama on Dockerhub(Source: Dockerhub)
You can find the ollama/ollama image available on Docker Hub.
Run the Ollama Container
Since we’re using an Nvidia GPU and have already set up the NVIDIA Container Toolkit environment (NVIDIA Container Toolkit), all we need to do now is run the following command.
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Using `-v` (volume), we mount `/root/.ollama` inside the Docker image to the `ollama` folder on Ubuntu.
# Using `-p` (port), we expose port `11434` from the container to the host.
# Note: If you check the tags of `ollama/ollama` on Docker Hub, you'll see that `ENV OLLAMA_HOST=0.0.0.0:11434` is set.
# This is important — without this setting, Ollama will be accessible inside the container, but not from outside the container.
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Unable to find image 'ollama/ollama:latest' locally
latest: Pulling from ollama/ollama
d9802f032d67: Pull complete
161508c220d5: Pull complete
a5fe86995597: Pull complete
dfe8fac24641: Pull complete
Digest: sha256:74a0929e1e082a09e4fdeef8594b8f4537f661366a04080e600c90ea9f712721
Status: Downloaded newer image for ollama/ollama:latest
2a42f842e4156469e6a4f8710c5344035db06c105bee63201881d1bd00875489
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ollama/ollama latest a67447f85321 3 days ago 3.45GB
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ docker ps -s
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
2a42f842e415 ollama/ollama "/bin/ollama serve" 8 hours ago Up 7 hours 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollama 11.4kB (virtual 3.45GB)
Let’s check the location of the Docker volume.
For more information on how to use Docker volumes, please refer to the link below:
Container Volume
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# The Docker volume is named `ollama`, and its location is `/var/lib/docker/volumes/ollama/_data`.
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ docker volume ls
DRIVER VOLUME NAME
local ollama
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ docker volume inspect ollama
[
{
"CreatedAt": "2025-03-21T21:47:36+09:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/ollama/_data",
"Name": "ollama",
"Options": null,
"Scope": "local"
}
]
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ su
Password:
root@DESKTOP-B7GM3C5:/home/jaoneol/dcai/test-ollama# cd /var/lib/docker/volumes/ollama/_data
root@DESKTOP-B7GM3C5:/var/lib/docker/volumes/ollama/_data# ls -lrt
total 16
-rw-r--r-- 1 root root 81 Mar 21 21:47 id_ed25519.pub
-rw------- 1 root root 387 Mar 21 21:47 id_ed25519
-rw------- 1 root root 7 Mar 21 22:13 history
drwxr-xr-x 3 root root 4096 Mar 22 05:22 models
root@DESKTOP-B7GM3C5:/var/lib/docker/volumes/ollama/_data#
Test the Ollama Container
Ollama has a REST API for running and managing models.
You can easily test it out.
1
2
3
4
curl http://localhost:11434/api/generate -d '{
"model": "gemma3",
"prompt":"What is the capital of America?"
}'
When you run it, you’ll see a message saying that gemma3:latest is not available.
Let’s pull gemma3:latest by running the following command.
docker exec -it ollama /bin/bashollama pull gemma3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ curl http://localhost:11434/api/generate -d '{
"model": "gemma3",
"prompt":"What is the capital of America?"
}'
{"error":"model 'gemma3' not found"
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ docker exec -it ollama /bin/bash
root@7f9deabefe82:/# ollama pull gemma3
pulling manifest
pulling 377655e65351... 100% ▕████████████████████████████████████▏ 3.3 GB
pulling e0a42594d802... 100% ▕████████████████████████████████████▏ 358 B
pulling dd084c7d92a3... 100% ▕████████████████████████████████████▏ 8.4 KB
pulling 0a74a8735bf3... 100% ▕████████████████████████████████████▏ 55 B
pulling ffae984acbea... 100% ▕████████████████████████████████████▏ 489 B
verifying sha256 digest
writing manifest
success
root@7f9deabefe82:/# ollama list
NAME ID SIZE MODIFIED
gemma3:latest c0494fe00251 3.3 GB 6 seconds ago
root@7f9deabefe82:/# exit
exit
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$ curl http://localhost:11434/api/generate -d '{
"model": "gemma3",
"prompt":"What is the capital of America?"
}'
{"model":"gemma3","created_at":"2025-03-21T20:52:02.874631088Z","response":"The","done":false}
......
{"model":"gemma3","created_at":"2025-03-21T20:52:03.659462344Z","response":"?","done":false}
{"model":"gemma3","created_at":"2025-03-21T20:52:03.670390259Z","response":"","done":true,"done_reason":"stop","context":[105,2364,107,3689,563,506,5279,529,5711,236881,106,107,105,4368,107,818,5279,529,506,3640,4184,529,5711,563,5213,42804,236764,622,236761,236780,99382,236743,108,1509,11979,573,9252,529,18693,236761,103453,236743,108,6294,611,1461,531,1281,4658,919,1003,7693,236764,622,236761,236780,236761,653,506,749,236761,236773,236761,3251,236881],"total_duration":8892756097,"load_duration":7656020945,"prompt_eval_count":16,"prompt_eval_duration":439450067,"eval_count":51,"eval_duration":796620275}
(base) jaoneol@DESKTOP-B7GM3C5:~/dcai/test-ollama$
In the previous section, we accessed the container and manually executed the pull command to load the model into Ollama. However, if you’re running this on a server, you’ll face the issue of needing to do this every time the container restarts. In the next post, we’ll explore how to automatically load a pre-specified model.
For reference, it’s also possible to execute the ollama pull command using Python — just for your information.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import subprocess
from langchain_ollama import ChatOllama
from ollama import Client
from ollama._types import ResponseError
model_name = 'gemma3:1b'
# 모델 존재 여부 확인 및 필요시 pull
def ensure_model_exists(model: str):
client = Client()
try:
models_info = client.list().get("models", [])
model_tags = [m.get("tag") for m in models_info if "tag" in m]
if model not in model_tags:
print(f'Model "{model}" not found locally. Pulling it...')
subprocess.run(["ollama", "pull", model], check=True)
except Exception as e:
print(f"모델 확인 또는 pull 중 오류 발생: {e}")
raise
# 모델 확인 및 가져오기
ensure_model_exists(model_name)
# LLM 사용
llm = ChatOllama(model=model_name, url="http://localhost:11434")
response = llm.invoke("AI의 미래에 대해 100자 내외로 알려줘")
print(response)