Insert data in Collection
Let's insert data in collection.
In this post, we will write a statement to insert sample data into the TennisNews collection within the ds2man database created in the previous post.
Prepare Sample Data
Let’s prepare sample data as shown below.
- Sample data
| Date | NewsPaper | Topic | News |
|---|---|---|---|
| 2024-09-09 | MBC | 2024 US Open Victory | Jannik Sinner (World No. 1, Italy) clinched the men’s singles title at the US Open tennis tournament. |
| 2024-09-10 | Yonhap News | US Open Victory | Jannik Sinner (World No. 1, Italy) clinched the men’s singles title at the US Open tennis tournament. |
| 2024-08-03 | Dong-A Ilbo | Olympic Final | Novak Djokovic and Carlos Alcaraz faced off in the men’s singles final at the 2024 Paris Olympics. |
| 2024-08-02 | Newsis | Andy Murray’s Retirement | British tennis star Andy Murray concluded his professional career at the 2024 Paris Olympics, sharing a lighthearted retirement message. |
| 2024-07-03 | Official Olympics Website | Wimbledon | Korea’s Kwon Soon-woo was eliminated in the first round of Wimbledon 2024, losing to Denmark’s Holger Rune. |
| 2024-11-13 | Chosun Ilbo | ATP Finals Victory | Jannik Sinner dominated men’s tennis in 2024, securing the ATP Finals title. |
Then, the data was extracted in dictionary format for insertion. The key point here is embedding. The details of embedding will be covered later (honestly, I’m still updating my knowledge as I study). For now, I will proceed using bge-m3, which is widely used for Korean embeddings. The embedding process is simple—just use the following command to perform embedding.
Additionally, after embedding, the data was converted into a dictionary format for insertion into the collection.
embedding_model = SentenceTransformer(f"./{MODEL_FOLDER}/{EMBED_MODEL}")embedding = embedding_model.encode(news, normalize_embeddings=True)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import pandas as pd
import numpy as np
MODEL_FOLDER = 'Pretrained_byGit'
EMBED_MODEL = "bge-m3" # BAAI/bge-m3
df = pd.read_excel('.\\Tennis_2024_news.xlsx', engine='openpyxl')
news = df['News'].tolist()
# Note. embedding like this.
embedding_model = SentenceTransformer(f"./{MODEL_FOLDER}/{EMBED_MODEL}")
embedding = embedding_model.encode(news, normalize_embeddings=True)
df['News_embedding'] = df['News'].apply(lambda x: embedding_model.encode(x, normalize_embeddings=True).tolist())
# the data convert into a dictionary format for insertion into the collection.
extracted_data = df.to_dict(orient='records')
extracted_data[0]
1
2
3
4
5
6
7
8
{'Date': 20240909,
'NewsPaper': 'MBC',
'Topic': '2024 US Open Victory',
'News': "Jannik Sinner (World No. 1, Italy) clinched the men's singles title at the US Open tennis tournament.",
'News_embedding': [-0.026207489892840385,
0.015767322853207588,
-0.05157271400094032,
...]
Insert Entities into the Collection
client.insert(MILVUS_COL_NAME, extracted_data)client.flush(MILVUS_COL_NAME)
1
2
3
4
5
6
7
8
9
10
11
12
13
from pymilvus import MilvusClient
client = MilvusClient(uri=MILVUS_URL)
client.using_database(MILVUS_DB_NAME)
# Insert data
insert_result = client.insert(MILVUS_COL_NAME, extracted_data)
print(f"Inserted count: {insert_result['insert_count']}")
# Note. Persist data into Milvus (Mandatory step)
client.flush(MILVUS_COL_NAME)
print("Milvus data preparation complete!")
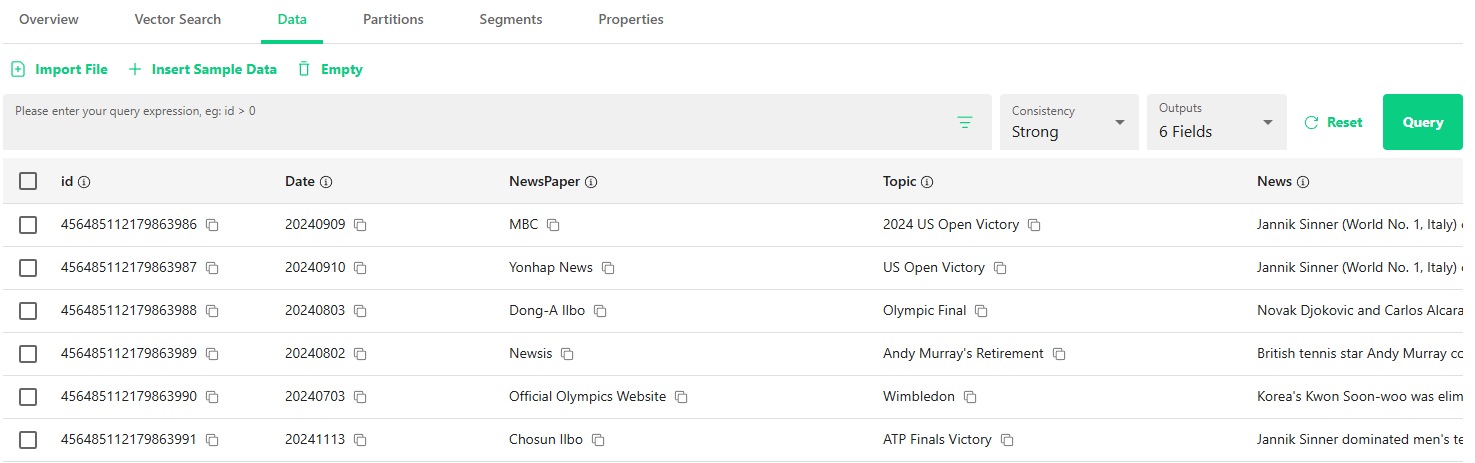
By checking through the Attu UI, you can verify that the sample data has been inserted into the collection.
 Attu UI
Attu UI