Collection and Index Creation
Let's create collection and index in Milvus.
Load libraray & Parameter definition
The pymilvus package and sentence_transformers, which provides embedding models, must be installed. The following code imports the required packages.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Import necessary classes and functions from pymilvus
from pymilvus import (
FieldSchema, # Schema definition for individual fields in a collection
CollectionSchema, # Defines the schema for an entire collection
DataType, # Defines data types used in fields
MilvusClient # Client class for connecting to Milvus server
)
# Import sentence_transformers for embedding generation
from sentence_transformers import SentenceTransformer
# I've commented out the parts commonly used as initial configuration.
# You can adjust the settings according to your own configuration.
MILVUS_URL = 'http://127.0.0.1:19530' # equal to 'http://localhost:19530'
MILVUS_DB_NAME = 'ds2man'
MILVUS_COL_NAME = 'TennisNews'
MODEL_FOLDER = 'Pretrained_byGit'
# Define the embedding model to be used (from sentence-transformers)
EMBED_MODEL = "bge-m3" # BAAI/bge-m3
EMBED_DIMENSION = 1024 # Dimension of embeddings
TENNISNEWS_COSINE_REF = 0.6 # Cosine similarity threshold value for similarity search queries
Create Collection
Step1) Connect to MilvusClient
1
2
3
4
5
6
# Connect to MilvusClient
# Note: The database should be created beforehand
client = MilvusClient(uri=MILVUS_URL)
client.using_database(MILVUS_DB_NAME) # Select the database to use
# Alternative connection with database name specified
# client = MilvusClient(uri=MILVUS_URL, db_name=MILVUS_DB_NAME)
Step2) Define Milvus Fields and Schema
1
2
3
4
5
6
7
8
9
10
11
# Define Schema for individual fields in a collection
fields = [
FieldSchema(name="id", dtype=DataType.INT64, auto_id=True),
FieldSchema(name="Date", dtype=DataType.INT64, max_length=10),
FieldSchema(name="NewsPaper", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="Topic", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="Embedding", dtype=DataType.FLOAT_VECTOR, dim=EMBED_DIMENSION)
]
# Defines the schema for an entire collection
schema = CollectionSchema(fields, description="Collection schema for Tennis News")
Step3) Create collection
1
2
3
4
5
6
7
8
9
10
11
# Create collection (skip if already exists)
if not client.has_collection(MILVUS_COL_NAME):
client.create_collection(
collection_name=MILVUS_COL_NAME,
schema=schema,
consistency_level="Strong" # 0 indicates eventual consistency
)
print(f"Collection '{MILVUS_COL_NAME}' created!")
else:
# client.drop_collection(MILVUS_COL_NAME) # Uncomment this line to delete the existing collection
print(f"Collection '{MILVUS_COL_NAME}' already exists.")
- Consistency Level : As a distributed vector database, Milvus offers multiple levels of consistency to ensure that each node or replica can access the same data during read and write operations. Currently, the supported levels of consistency include Strong, Bounded, Eventually, and Session, with Bounded being the default level of consistency used. By default, Milvus uses Bounded Staleness.
| Consistency Level | Description |
|---|---|
| Strong | The strictest consistency level. Ensures that all nodes return the latest data, guaranteeing real-time consistency. |
| Bounded Staleness | Ensures consistency within a bounded timeframe. While updates may not be immediately visible, consistency is guaranteed after a certain period. This is the default setting in Milvus. |
| Session | Ensures that writes within the same client session are immediately visible. However, data consistency is not guaranteed across different sessions. |
| Eventually | The weakest consistency level. Data may be temporarily inconsistent across nodes, but all replicas will eventually converge to the same state. |
Step4) Create Index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Create Index
# To create an index for a collection, use prepare_index_params() to define the parameters, then use create_index().
# 4.1. Set up the index parameters
index_params = client.prepare_index_params()
# 4.2. Add an index on the vector field
index_params.add_index(
field_name="News_embedding",
index_name="idx1",
index_type="FLAT", # Options: "FLAT", "IVF_FLAT", "IVF_PQ", "HNSW"
metric_type="COSINE" # Options: "L2", "IP", "COSINE"
)
# If you want, you can add an index as shown below.
# index_params.add_index(
# field_name="Topic",
# index_name="idx2",
# index_type="Trie"
# )
# 4.3. Create an index
client.create_index(collection_name=MILVUS_COL_NAME, index_params=index_params)
print("Index created!")
# 5. Load Collection
# Note: You should use `load_collection` to optimize vector search performance and manage resources efficiently.
client.load_collection(MILVUS_COL_NAME)
At this stage, the key parts you should pay close attention to are index_type and metric_type.
For index_type, various search algorithms exist such as “FLAT,” “IVF_FLAT,” “IVF_PQ,” and “HNSW.” Honestly, I don’t fully understand the details. However, the most commonly used combination is “FLAT” with “COSINE.” Of course, depending on the data we’ll be using, we may need to redefine the index type and metric accordingly.
For more detailed information, you might want to refer to Milvus-Index. Additionally, Pinecone provides an excellent explanation of ANN algorithms.
| Metric Types | Index Types |
|---|---|
| - Euclidean distance (L2) - Inner product (IP) - Cosine similarity (COSINE) | - FLAT - IVF_FLAT - IVF_SQ8 - IVF_PQ - GPU_IVF_FLAT - GPU_IVF_PQ - HNSW - DISKANN |
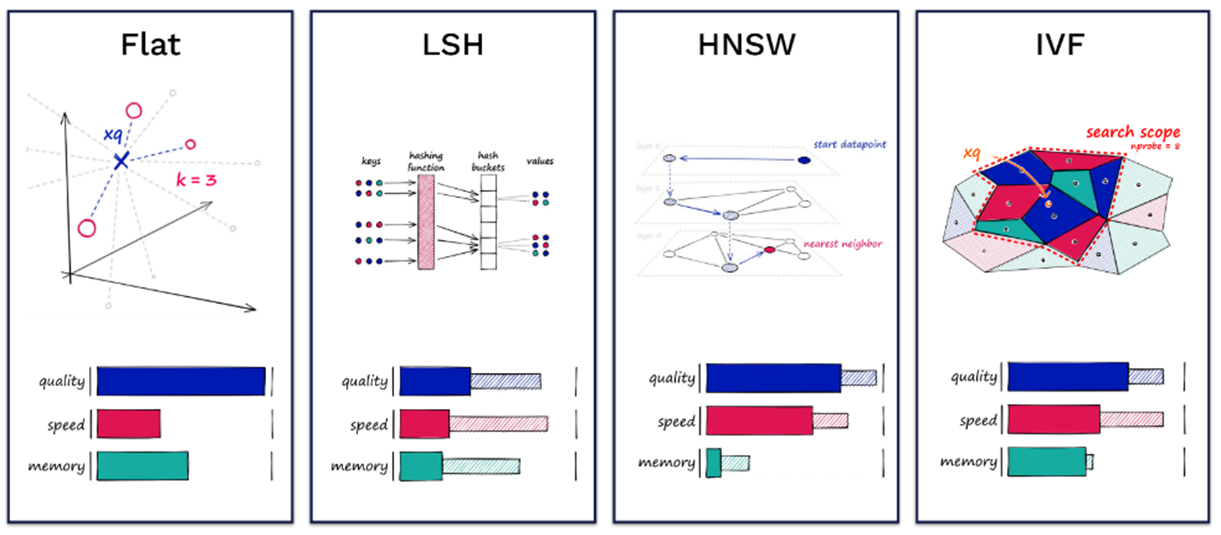 ANN Algorithms(Source: Pinecone)
ANN Algorithms(Source: Pinecone)
Use Attu
You can verify that the collection has been successfully created by checking through the Attu UI.
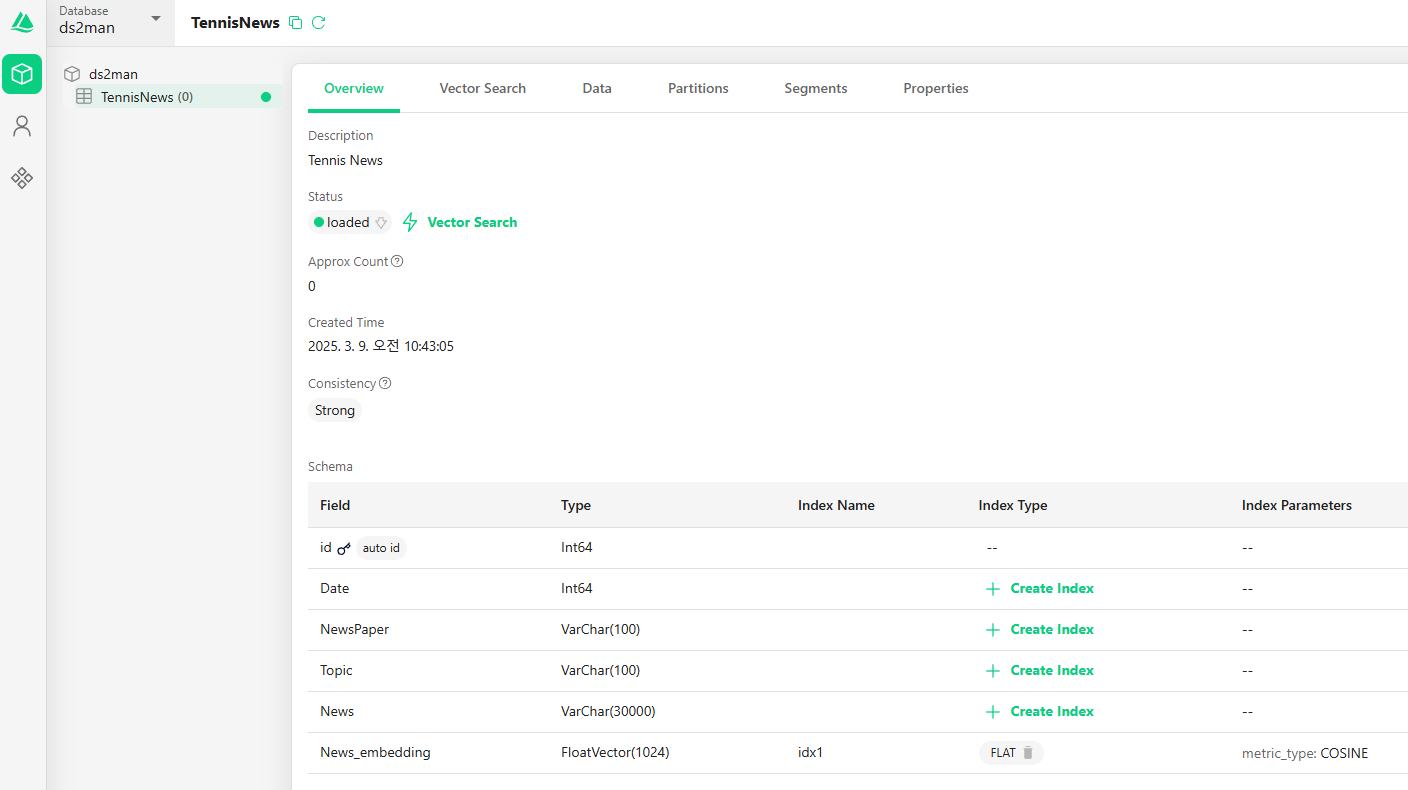 Attu UI
Attu UI