AgentWorkflow
Let’s Understanding `Agent Workflow` in LangGraph.
An Agent Workflow leverages the built-in agent systems provided by LangGraph, such as the create_react_agent() functions.
Through the previous post, we covered the basic concepts, and in this post, we’ll write the actual code.
There are five main steps involved. The same applies to the Agent-like Workflow. The key difference is that, in the Agent-like Workflow, you manually construct the agent’s behavior by separately defining the Tool Node and the LLM with tools Node and connecting them directly within LangGraph.
- Define the Required
ToolsandAgentfor Nodes - Define the State
- Define the Nodes(
Agent Node) - Define Conditional Edges
- Construct the Graph
1. Define the Required Tools for Nodes
Tools
Tools enhance the LLM’s functionality when additional capabilities are needed. For the definition of tools, refer to the previous post: LangChain-Tools.
1
2
3
4
5
6
from ai.tools.get_time import get_current_datetime_tool
from ai.tools.repl import python_repl_tool
from ai.tools.search_web import googlenews_search_tool, tavily_search_tool
from ai.tools.retriever import pdf_retriever_tool
my_tools = [python_repl_tool, tavily_search_tool, googlenews_search_tool, get_current_datetime_tool, pdf_retriever_tool]
Agent
Define the agent using create_react_agent.
1
2
3
4
5
6
7
8
9
10
11
llm = ChatOpenAI(
model=openai_api_model,
openai_api_base=openai_api_base,
openai_api_key=openai_api_key
)
agent = create_react_agent(
model=llm,
tools=my_tools,
state_modifier="You are a helpful assistant"
)
Execution
1
2
3
4
5
6
7
8
9
10
11
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
result = agent.invoke(inputs)
result
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{'messages': [
HumanMessage(content='오늘의 AI 뉴스 알려줘.', additional_kwargs={}, response_metadata={}, id='3f49807b-cc66-4995-b232-83a2fa734c0c'),
AIMessage(content='',
additional_kwargs={'tool_calls': [{'id': 'dcw1few0r', 'function': {'arguments': '{"query":"AI 뉴스"}', 'name': 'googlenews_search_tool'}, 'type': 'function', 'index': 0}],
'refusal': None},
response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 978, 'total_tokens': 1005, 'completion_tokens_details': None, 'prompt_tokens_details': None},
'model_name': 'meta-llama/llama-4-maverick',
'system_fingerprint': 'fp_565109a0df',
'finish_reason': 'tool_calls',
'logprobs': None},
id='run--679c858e-fb52-4d2d-9b6e-ddac577a928c-0',
tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI 뉴스'}, 'id': 'dcw1few0r', 'type': 'tool_call'}],
usage_metadata={'input_tokens': 978, 'output_tokens': 27, 'total_tokens': 1005, 'input_token_details': {}, 'output_token_details': {}}),
ToolMessage(content='- 엔비디아 칩 1.4조어치 중국으로 밀수..."시장에서 해산물처럼 구입" - AI타임스\n- 美 AI칩 수출 통제 이후에도 최소 10억달러 AI칩 中 밀수 - 조선일보\n- AI반도체 대중수출 규제 있으나마나...중국 암시장에 널려있는 엔비디아 칩 - 매일경제',
name='googlenews_search_tool',
id='e230a4cd-c875-4b60-94d2-95156c0a4c61',
tool_call_id='dcw1few0r'),
AIMessage(content='AI 뉴스를 찾았습니다. 관련 기사 몇 가지를 소개해 드리겠습니다.\n\n1. "엔비디아 칩 1.4조어치 중국으로 밀수...\\"시장에서 해산물처럼 구입\\"" - AI타임스\n2. "美 AI칩 수출 통제 이후에도 최소 10억달러 AI칩 中 밀수" - 조선일보\n3. "AI반도체 대중수출 규제 있으나마나...중국 암시장에 널려있는 엔비디아 칩" - 매일경제\n\n자세한 내용은 원문을 참고하시기 바랍니다.',
additional_kwargs={'refusal': None},
response_metadata={'token_usage': {'completion_tokens': 117, 'prompt_tokens': 737, 'total_tokens': 854, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None},
id='run--6a579bd4-dbb9-4f66-bdc6-152b76bf793d-0',
usage_metadata={'input_tokens': 737, 'output_tokens': 117, 'total_tokens': 854, 'input_token_details': {}, 'output_token_details': {}})
]
}
2. Define the State
1
2
3
4
5
6
class GraphState(TypedDict):
# The line below technically works, but since it's just defined as a list,
# it's unclear whether it's a list of int, str, or dict.
# IDEs or tools like mypy that rely on type hints may not provide accurate warnings.
# messages: Annotated[list, add_messages]
messages: Annotated[Sequence[BaseMessage], add_messages]
3. Define the Nodes
1
2
def run_agent(state: GraphState) -> GraphState:
response = agent.invoke({"messages": state["messages"]})
4. Define Conditional Edges
In Step 3, we used create_react_agent() to connect the LLM with my_tools. As a result, implementing conditional branching logic isn’t necessary. However, we implemented tools_condition manually for reference. Just take it as a reference.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def my_tools_condition(
state: GraphState,
):
if messages := state.get("messages", []):
# Extract the most recent AI message
ai_message = messages[-1]
else:
# Raise an exception if there are no messages in the input state
raise ValueError(f"No messages found in input state to tool_edge: {state}")
# If the AI message contains a tool call, return "tools"
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
# Tool call exists, return "tools"
return "tools"
# If no tool call exists, return "END"
return END
5. Construct the Graph
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Construct the Graph
workflow = StateGraph(GraphState)
workflow.add_node("MyAgent", run_agent)
workflow.set_entry_point("MyAgent")
workflow.add_edge("MyAgent", END)
# Checkpoint configuration (memory storage)
# memory = MemorySaver()
os.makedirs("./cache", exist_ok=True)
conn = sqlite3.connect("./cache/checkpoints.sqlite", check_same_thread=False)
memory = SqliteSaver(conn)
agent_app = workflow.compile(checkpointer=memory)
# Graph visualization
visualize_graph(agent_app, xray=True)
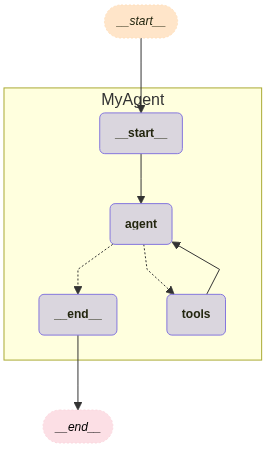 Agent Workflow
Agent Workflow
Execution and evaluation
invoke
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
result = agent_app.invoke(inputs, config)
print("====" * 4)
print(f"Total number of messages: {len(result['messages'])}")
print("====" * 4)
print("All messages:")
for idx in range(len(result['messages'])):
print(f"{result['messages'][idx]}")
print("====" * 4)
print(f"Final response:\n{result['messages'][-1].content}")
print("====" * 4)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
================
Total number of messages: 4
================
All messages:
content='오늘의 AI 뉴스 알려줘.' additional_kwargs={} response_metadata={} id='db1b8690-2de0-4b47-a8b0-fc9089ad2433'
content='' additional_kwargs={'tool_calls': [{'id': 'chatcmpl-tool-87c816618f7b4ea29f1c67a04949473a', 'function': {'arguments': '{"query": "AI"}', 'name': 'googlenews_search_tool'}, 'type': 'function', 'index': 0}], 'refusal': None} response_metadata={'token_usage': {'completion_tokens': 20, 'prompt_tokens': 696, 'total_tokens': 716, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run--5968aa4d-1d49-48b1-a204-ab210b37b884-0' tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI'}, 'id': 'chatcmpl-tool-87c816618f7b4ea29f1c67a04949473a', 'type': 'tool_call'}] usage_metadata={'input_tokens': 696, 'output_tokens': 20, 'total_tokens': 716, 'input_token_details': {}, 'output_token_details': {}}
content='- 오픈AI, 다음달 \'GPT-5\' 출시…\'o3 추론\' 통합해 AI 초격차 벌리나 - 지디넷코리아\n- 올트먼 “내가 쓸모없다고 느꼈다”...오픈AI, 더 똑똑해진 ‘GPT-5′ 내달 출시 - 조선일보\n- 메타, MSL 수석 과학자에 오픈AI 출신 임명..."르쿤은 37살 연하 왕 CAIO에 보고" - AI타임스' name='googlenews_search_tool' id='0dd32371-5845-48ae-8022-e842c722f6b2' tool_call_id='chatcmpl-tool-87c816618f7b4ea29f1c67a04949473a'
content='현재 AI 뉴스는 다음과 같습니다.\n\n1. 오픈AI, 다음달 \'GPT-5\' 출시…\'o3 추론\' 통합해 AI 초격차 벌리나 - 지디넷코리아\n2. 올트먼 “내가 쓸모없다고 느꼈다”...오픈AI, 더 똑똑해진 ‘GPT-5′ 내달 출시 - 조선일보\n3. 메타, MSL 수석 과학자에 오픈AI 출신 임명...\\"르쿤은 37살 연하 왕 CAIO에 보고\\" - AI타임스' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 116, 'prompt_tokens': 763, 'total_tokens': 879, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run--6b944a2d-0ec7-427a-9d36-9f248234fac3-0' usage_metadata={'input_tokens': 763, 'output_tokens': 116, 'total_tokens': 879, 'input_token_details': {}, 'output_token_details': {}}
================
Final response:
현재 AI 뉴스는 다음과 같습니다.
1. 오픈AI, 다음달 'GPT-5' 출시…'o3 추론' 통합해 AI 초격차 벌리나 - 지디넷코리아
2. 올트먼 “내가 쓸모없다고 느꼈다”...오픈AI, 더 똑똑해진 ‘GPT-5′ 내달 출시 - 조선일보
3. 메타, MSL 수석 과학자에 오픈AI 출신 임명...\"르쿤은 37살 연하 왕 CAIO에 보고\" - AI타임스
================
stream
LangGraph provides three stream_mode options, each returning different output formats depending on the selected mode:
message: Atuplethat streams messages from each node. This also supports token-level streaming output from the LLM.values: Adictthat streams the values of the graph, representing the entire state of the graph after each node is executed.update: Adictthat streams updates to the graph, meaning changes to the graph state after each node execution.
In the case of an agent created through create_react_agent, the internal results are not being output.
stream_mode=”messages”
- In the case of
stream_mode="messages":- You can output only the messages emitted from a specific node using
metadata["langgraph_node"].
- You can output only the messages emitted from a specific node using
- (Example) To output only the messages from the chatbot node:
metadata["langgraph_node"] == "chatbot"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
for chunk_msg, metadata in agent_app.stream(inputs, config, stream_mode="messages"):
# if isinstance(chunk_msg, AIMessageChunk):
# print(chunk_msg.content, end="", flush=True)
if metadata["langgraph_node"] == "MyAgent":
print(chunk_msg.content, end="", flush=True)
1
최근 AI 뉴스는 LG가 하이브리드 AI '엑사원4.0'을 공개하고, 코오롱베니트가 LG 엑사원 기반 AI 관제 패키지를 개발하는 등 다양한 분야에서 인공지능 기술이 발전하고 있습니다. 자세한 내용은 관련 기사를 참고하시기 바랍니다.
stream_mode=”values”
The values mode outputs the current state values at each step.
step.items()
key: The key of the statevalue: The value corresponding to the state key- ```python config = RunnableConfig(recursion_limit=10, configurable={“thread_id”: random_uuid()})
question = “오늘의 AI 뉴스 알려줘.” inputs = { “messages”: [ HumanMessage( content=question ) ], }
for step in agent_app.stream(inputs, config, stream_mode=”values”): # print(f”Step Output: {step}”) for key, value in step.items(): print(f”\n[ {key} ]”) value[“messages”][-1].pretty_print()
1
2
3
4
5
6
7
8
9
10
11
```bash
[ messages ]
================================ Human Message =================================
오늘의 AI 뉴스 알려줘.
[ messages ]
================================== Ai Message ==================================
최근 AI 관련 뉴스입니다. LG는 하이브리드 AI '엑사원4.0'을 공개하며 글로벌 프론티어 성능에 도달했다고 발표했습니다. 또한 코오롱베니트는 LG 엑사원 기반 AI 관제 패키지를 개발했으며, 인공지능 안전 관제 시스템 'AI 비전 인텔리전스'를 발표했습니다. 이러한 발전은 AI 기술의 지속적인 성장을 보여주고 있습니다.
stream_mode=”updates”
The updates mode outputs only the updated state for each step.
- The output is a
dictionarywhere the key is the node name and the value is the updated result.
step.items()
key: The name of the nodevalue: The output at that node step (a dictionary containing multiple key-value pairs)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
for step in agent_app.stream(inputs, config, stream_mode="updates"):
# print(f"Step Output: {step}")
for key, value in step.items():
print(f"\n[ {key} ]")
value["messages"][-1].pretty_print()
1
2
3
4
[ MyAgent ]
================================== Ai Message ==================================
Today's AI news includes: 1. Human Technology signed a 10 billion won supply contract with Markt for AI speakers. 2. Palantir, Dell, and Iridium were added to the S&P 500 index. 3. TorisSquare held a 'Tech Day' at Cades 2024.