Agent-like Workflow
Let’s Understanding `Agent-like Workflow` in LangGraph.
An Agent-like Workflow manually implements agent-like logic by explicitly composing workflow nodes using frameworks like LangGraph. Developers configure individual nodes (e.g., LLM nodes, tool nodes, conditional edges) to replicate agent behaviors. I expect to primarily adopt this approach when building with LangGraph going forward.
Through the previous post , we covered the basic concepts, and in this post, we’ll write the actual code.
The process consists of five main steps. You define both the Tool Node and the LLM with tools Node. The LLM with tools plays the role of informing the LLM about the available tools it can call. This is typically represented in the tool_calls field, which includes information such as name, args, and type. Then, you define the shared State, create the necessary Nodes (Tool Node, LLM with tools Node), and finally build, compile, and visualize the LangGraph.
- Define the Required
ToolsandLLM with toolsfor Nodes - Define the State
- Define the Nodes(
Tool NodeandLLM with tools Node) - Define Conditional Edges
- Construct the Graph
1. Define the Required Tools for Nodes
Tools
Tools enhance the LLM’s functionality when additional capabilities are needed. For the definition of tools, refer to the previous post: LangChain-Tools.
1
2
3
4
5
6
from ai.tools.get_time import get_current_datetime_tool
from ai.tools.repl import python_repl_tool
from ai.tools.search_web import googlenews_search_tool, tavily_search_tool
from ai.tools.retriever import pdf_retriever_tool
my_tools = [python_repl_tool, tavily_search_tool, googlenews_search_tool, get_current_datetime_tool, pdf_retriever_tool]
LLM with tools
The LLM with tools plays the role of informing the LLM about the available tools it can call. This is typically represented in the tool_calls field, which includes information such as name, args, and type.
1
2
3
4
5
6
llm_with_tools = ChatOpenAI(
model=openai_api_model, # OpenRouter 모델 이름
openai_api_base=openai_api_base,
openai_api_key=openai_api_key,
max_tokens=1000
).bind_tools(tools=my_tools)
Execution
1
2
3
4
5
6
7
8
9
10
11
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
result = llm_with_tools.invoke(inputs["messages"])
result
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
AIMessage(
content='',
additional_kwargs={'tool_calls': [{'id': 't6aqe05j7',
'function': {'arguments': '{"query":"AI 뉴스"}',
'name': 'googlenews_search_tool'},
'type': 'function', 'index': 0}],
'refusal': None},
response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 973, 'total_tokens': 1000,
'completion_tokens_details': None, 'prompt_tokens_details': None},
'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_c527aa4474',
'finish_reason': 'tool_calls', 'logprobs': None},
id='run--38f4292d-ad9c-4c9c-ba8f-a1362334f30e-0',
# Note.
# `tool_calls` field, includes information such as `name`, `args`, and `type`.
tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI 뉴스'},
'id': 't6aqe05j7', 'type': 'tool_call'}],
usage_metadata={'input_tokens': 973, 'output_tokens': 27, 'total_tokens': 1000, 'input_token_details': {},
'output_token_details': {}}
)
2. Define the State
1
2
3
4
5
6
class GraphState(TypedDict):
# The line below technically works, but since it's just defined as a list,
# it's unclear whether it's a list of int, str, or dict.
# IDEs or tools like mypy that rely on type hints may not provide accurate warnings.
# messages: Annotated[list, add_messages]
messages: Annotated[Sequence[BaseMessage], add_messages]
3. Define the Nodes
Define the tool node using ToolNode.
1
tool_node = ToolNode(tools=my_tools)
Execution
By passing multiple tool calls to the tool_calls parameter of an AIMessage, you can execute them in parallel using a ToolNode.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
message_with_single_tool_call = AIMessage(
content="",
tool_calls=[
{
"name": "googlenews_search_tool",
"args": {"query": "AI"},
"id": "tool_call_id",
"type": "tool_call",
},
{
"name": "python_repl_tool",
"args": {"query": "print(1+2+3+4)"},
"id": "tool_call_id",
"type": "tool_call",
},
],
)
tool_node.invoke({"messages": [message_with_single_tool_call]})
1
2
{'messages': [ToolMessage(content='- 오픈AI, 메타에 AI 인재 또 빼앗겨...\'o1\' 만든 한국인도 떠났다 - 지디넷코리아\n- 메타, 오픈AI 연구원 2명 추가 영입...한국인도 포함 - AI타임스\n- "연봉 1400억이면 될까요?"…한국인 포함 AI 연구원 영입전쟁 - 네이트 뉴스', name='googlenews_search_tool', tool_call_id='tool_call_id'),
ToolMessage(content='10\n', name='python_repl_tool', tool_call_id='tool_call_id')]}
Define the llm with tools node
1
2
3
def run_llm_with_tools(state: GraphState) -> GraphState:
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
4. Define Conditional Edges
The module tools_condition is available from langgraph.prebuilt.
You can either use this built-in condition directly or implement your own version with the same functionality.
In this example, we’ll demonstrate how to implement it manually.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def my_tools_condition(
state: GraphState,
):
if messages := state.get("messages", []):
# Extract the most recent AI message
ai_message = messages[-1]
else:
# Raise an exception if there are no messages in the input state
raise ValueError(f"No messages found in input state to tool_edge: {state}")
# If the AI message contains a tool call, return "tools"
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
# Tool call exists, return "tools"
return "tools"
# If no tool call exists, return "END"
return END
5. Construct the Graph
To enable multi-turn conversations, I will add checkpointing. Although MemorySaver is one way to create a checkpointer, it does not allow for permanent storage of conversation history.
Therefore, I plan to use the SqliteSaver method, which is based on SQLite.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Construct the Graph
workflow = StateGraph(GraphState)
workflow.add_node("MyLLM", run_llm_with_tools)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("MyLLM")
# Setting Conditional Edges
## All three are equivalent!
workflow.add_conditional_edges("MyLLM", tools_condition)
# workflow.add_conditional_edges("MyLLM", my_tools_condition)
# workflow.add_conditional_edges(
# source="MyLLM",
# path=my_tools_condition,
# # If the return value of `route_tools` is `"tools"`, route to the `"tools"` node; otherwise, route to the `END` node.
# path_map={"tools": "tools", END: END},
# )
# Checkpoint configuration (memory storage)
# memory = MemorySaver()
os.makedirs("./cache", exist_ok=True)
conn = sqlite3.connect("./cache/checkpoints.sqlite", check_same_thread=False)
memory = SqliteSaver(conn)
llm_app = workflow.compile(checkpointer=memory)
# Graph visualization
visualize_graph(llm_app, xray=True)
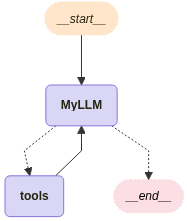 Agent-like Workflow
Agent-like Workflow
Execution and evaluation
invoke
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
result = llm_app.invoke(inputs, config)
print("====" * 4)
print(f"Total number of messages: {len(result['messages'])}")
print("====" * 4)
print("All messages:")
for idx in range(len(result['messages'])):
print(f"{result['messages'][idx]}")
print("====" * 4)
print(f"Final response:\n{result['messages'][-1].content}")
print("====" * 4)
1
2
3
4
5
6
7
8
9
10
11
12
================
Total number of messages: 4
================
All messages:
content='오늘의 AI 뉴스 알려줘.' additional_kwargs={} response_metadata={} id='5fe4b6b3-00bd-4a70-8707-8c34bd680d45'
content='' additional_kwargs={'tool_calls': [{'id': '0', 'function': {'arguments': '{"query": "AI 뉴스"}', 'name': 'googlenews_search_tool'}, 'type': 'function', 'index': 0}], 'refusal': None} response_metadata={'token_usage': {'completion_tokens': 12, 'prompt_tokens': 773, 'total_tokens': 785, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run--9c140487-87a9-4c8b-991f-f3c8ffb7e421-0' tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI 뉴스'}, 'id': '0', 'type': 'tool_call'}] usage_metadata={'input_tokens': 773, 'output_tokens': 12, 'total_tokens': 785, 'input_token_details': {}, 'output_token_details': {}}
content="- 메타, 오픈AI 연구원 2명 추가 영입...한국인도 포함 - AI타임스\n- 메타 대우가 얼마나 좋으면... 오픈 AI 한국인 연구원도 옮겼다 - 조선일보\n- 오픈AI, 메타에 AI 인재 또 빼앗겨...'o1' 만든 한국인도 떠났다 - 지디넷코리아" name='googlenews_search_tool' id='57d552aa-060c-4f1a-9946-4091138f665d' tool_call_id='0'
content='메타와 오픈AI가 최근 연구원 영입 경쟁에 나선 것으로 나타났다. 최근 메타는 오픈AI 출신 연구원 2명을 영입했으며, 이들 중 한 명은 한국인인 것으로 알려졌다. 이 소식은 조선일보와 지디넷코리아 등 여러 매체에서 보도되었다.' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 62, 'prompt_tokens': 1088, 'total_tokens': 1150, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_565109a0df', 'finish_reason': 'stop', 'logprobs': None} id='run--aabbe605-c4c1-4836-815d-1607d040ba50-0' usage_metadata={'input_tokens': 1088, 'output_tokens': 62, 'total_tokens': 1150, 'input_token_details': {}, 'output_token_details': {}}
================
Final response:
메타와 오픈AI가 최근 연구원 영입 경쟁에 나선 것으로 나타났다. 최근 메타는 오픈AI 출신 연구원 2명을 영입했으며, 이들 중 한 명은 한국인인 것으로 알려졌다. 이 소식은 조선일보와 지디넷코리아 등 여러 매체에서 보도되었다.
================
stream
LangGraph provides three stream_mode options, each returning different output formats depending on the selected mode:
message: Atuplethat streams messages from each node. This also supports token-level streaming output from the LLM.
1
2
3
4
5
6
7
8
9
10
11
12
for chunk_msg, metadata in llm_app.stream(inputs, config, stream_mode="messages"):
print(f"Step Output: {chunk_msg}, {metadata}")
"""
# Step Output: content='' additional_kwargs={} response_metadata={'finish_reason': 'tool_calls', 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_7c27472e1f'} id='run--7498a58e-6ef9-41c5-8d02-c4da2ff72abb', {'thread_id': '771c4fcd-9727-4a1b-b34c-ef61c6513307', 'langgraph_step': 1, 'langgraph_node': 'MyLLM', 'langgraph_triggers': ['start:MyLLM'], 'langgraph_path': ('__pregel_pull', 'MyLLM'), 'langgraph_checkpoint_ns': 'MyLLM:d9ec6771-638d-4f14-ef77-d55ec73513b6', 'checkpoint_ns': 'MyLLM:d9ec6771-638d-4f14-ef77-d55ec73513b6', 'ls_provider': 'openai', 'ls_model_name': 'meta-llama/llama-4-maverick', 'ls_model_type': 'chat', 'ls_temperature': 0.7}
# Step Output: content='' additional_kwargs={} response_metadata={} id='run--7498a58e-6ef9-41c5-8d02-c4da2ff72abb' usage_metadata={'input_tokens': 973, 'output_tokens': 27, 'total_tokens': 1000, 'input_token_details': {}, 'output_token_details': {}}, {'thread_id': '771c4fcd-9727-4a1b-b34c-ef61c6513307', 'langgraph_step': 1, 'langgraph_node': 'MyLLM', 'langgraph_triggers': ['start:MyLLM'], 'langgraph_path': ('__pregel_pull', 'MyLLM'), 'langgraph_checkpoint_ns': 'MyLLM:d9ec6771-638d-4f14-ef77-d55ec73513b6', 'checkpoint_ns': 'MyLLM:d9ec6771-638d-4f14-ef77-d55ec73513b6', 'ls_provider': 'openai', 'ls_model_name': 'meta-llama/llama-4-maverick', 'ls_model_type': 'chat', 'ls_temperature': 0.7}
# Step Output: content='[{"url": "https://news.google.com/rss/articles/CBMiWkFVX3lxTFBkUERLeW1tMVNUeXFBSk9HWVF6UXNQN0dTR2c5bk9BUnVUWXFVSWdCQ0VlWjJlb1ZZdUZ4dGxsSXJ2WktvWWozMXQ0NkQ1S2FKZ2kxWVhSUjZQZ9IBVEFVX3lxTE9xWDktOE5fMDh4WUk0dlhXeUk3MHhhbE9HSWNUeW15NDN4NmZXQV9xVVdTR0I5dG80NEtCazc2NllzYTlIdm05Vy1zaVhONmtLODdBaQ?oc=5", "content": "\\"직장인 친구들 안 부럽다\\"…月 600만원 버는 \'AI 대체불가\' 직업 - 한국경제"}, {"url": "https://news.google.com/rss/articles/CBMiWkFVX3lxTE5UOHdEOUdwZG9odjdKRF9QUnlaangzcFdCRUEyNFVrUUZsN2JQN3NuRlphTHJqOTVNMy0zOENab0NKYlFRQjNLd1haaUtrME0wMmw4MkctcjQxZ9IBVEFVX3lxTE5saXVleVZueXZNSzFLU1lYMnU5NVBHR3M0NjQxS25JRHJYWjk0dzJfSkdrR21iZ1AzT05jQURLc29UOHVEWXN0bFZfc3ROb0I4dmxRdg?oc=5", "content": "\'챗GPT\'가 아니었다…한국인이 가장 오래 쓰는 AI 챗봇 앱은? - 한국경제"}, {"url": "https://news.google.com/rss/articles/CBMiakFVX3lxTE11SWwyZjJmcDNzajBHX0stXzlJWVJfMGFZV0J5ODRKT2o4ZEtwR0o3bkczLUlmUzZMTVl2X3dGa3cwXzk2QU5LN2VqdjMySjVWbjh2NzZNNWNqN01sbFVaUU1Ud1d6elZfTmc?oc=5", "content": "오픈AI, MS 앱 없어도 엑셀·파워포인트 만드는 \'챗GPT\' 기능 개발 - AI타임스"}]' name='googlenews_search_tool' id='471a8dda-a518-4f4a-99e6-9678eaa4542e' tool_call_id='y8tebq05c', {'thread_id': '771c4fcd-9727-4a1b-b34c-ef61c6513307', 'langgraph_step': 2, 'langgraph_node': 'tools', 'langgraph_triggers': ['branch:MyLLM:tools_condition:tools'], 'langgraph_path': ('__pregel_pull', 'tools'), 'langgraph_checkpoint_ns': 'tools:a83f53ef-d168-b5e7-9327-1507a87735b0'}
# Step Output: content='' additional_kwargs={} response_metadata={} id='run--e612ad63-51fe-4f27-bd6a-72de4cb87b30', {'thread_id': '771c4fcd-9727-4a1b-b34c-ef61c6513307', 'langgraph_step': 3, 'langgraph_node': 'MyLLM', 'langgraph_triggers': ['tools'], 'langgraph_path': ('__pregel_pull', 'MyLLM'), 'langgraph_checkpoint_ns': 'MyLLM:259ed9e1-f3ac-a813-d5da-a1287847e2e2', 'checkpoint_ns': 'MyLLM:259ed9e1-f3ac-a813-d5da-a1287847e2e2', 'ls_provider': 'openai', 'ls_model_name': 'meta-llama/llama-4-maverick', 'ls_model_type': 'chat', 'ls_temperature': 0.7}
# Step Output: content='최근' additional_kwargs={} response_metadata={} id='run--e612ad63-51fe-4f27-bd6a-72de4cb87b30', {'thread_id': '771c4fcd-9727-4a1b-b34c-ef61c6513307', 'langgraph_step': 3, 'langgraph_node': 'MyLLM', 'langgraph_triggers': ['tools'], 'langgraph_path': ('__pregel_pull', 'MyLLM'), 'langgraph_checkpoint_ns': 'MyLLM:259ed9e1-f3ac-a813-d5da-a1287847e2e2', 'checkpoint_ns': 'MyLLM:259ed9e1-f3ac-a813-d5da-a1287847e2e2', 'ls_provider': 'openai', 'ls_model_name': 'meta-llama/llama-4-maverick', 'ls_model_type': 'chat', 'ls_temperature': 0.7}
# Step Output: content=' AI' additional_kwargs={} response_metadata={} id='run--e612ad63-51fe-4f27-bd6a-72de4cb87b30', {'thread_id': '771c4fcd-9727-4a1b-b34c-ef61c6513307', 'langgraph_step': 3, 'langgraph_node': 'MyLLM', 'langgraph_triggers': ['tools'], 'langgraph_path': ('__pregel_pull', 'MyLLM'), 'langgraph_checkpoint_ns': 'MyLLM:259ed9e1-f3ac-a813-d5da-a1287847e2e2', 'checkpoint_ns': 'MyLLM:259ed9e1-f3ac-a813-d5da-a1287847e2e2', 'ls_provider': 'openai', 'ls_model_name': 'meta-llama/llama-4-maverick', 'ls_model_type': 'chat', 'ls_temperature': 0.7}
......
"""
values: Adictthat streams the values of the graph, representing the entire state of the graph after each node is executed.
1
2
3
4
5
6
7
8
9
for step in llm_app.stream(inputs, config, stream_mode="values"):
print(f"Step Output: {step}")
"""
# Step Output: {'messages': [HumanMessage(content='오늘의 AI 뉴스 알려줘.', additional_kwargs={}, response_metadata={}, id='b6e54454-d9b2-420e-b1aa-c4bc98b0a521')]}
# Step Output: {'messages': [HumanMessage(content='오늘의 AI 뉴스 알려줘.', additional_kwargs={}, response_metadata={}, id='b6e54454-d9b2-420e-b1aa-c4bc98b0a521'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'x5dfrvj4m', 'function': {'arguments': '{"query":"AI 뉴스"}', 'name': 'googlenews_search_tool'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 973, 'total_tokens': 1000, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_c527aa4474', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--dbf0ee85-4c67-454e-add8-af66bc38ae2f-0', tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI 뉴스'}, 'id': 'x5dfrvj4m', 'type': 'tool_call'}], usage_metadata={'input_tokens': 973, 'output_tokens': 27, 'total_tokens': 1000, 'input_token_details': {}, 'output_token_details': {}})]}
# Step Output: {'messages': [HumanMessage(content='오늘의 AI 뉴스 알려줘.', additional_kwargs={}, response_metadata={}, id='b6e54454-d9b2-420e-b1aa-c4bc98b0a521'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'x5dfrvj4m', 'function': {'arguments': '{"query":"AI 뉴스"}', 'name': 'googlenews_search_tool'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 973, 'total_tokens': 1000, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_c527aa4474', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--dbf0ee85-4c67-454e-add8-af66bc38ae2f-0', tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI 뉴스'}, 'id': 'x5dfrvj4m', 'type': 'tool_call'}], usage_metadata={'input_tokens': 973, 'output_tokens': 27, 'total_tokens': 1000, 'input_token_details': {}, 'output_token_details': {}}), ToolMessage(content='[{"url": "https://news.google.com/rss/articles/CBMiakFVX3lxTE9mYm1WUV9SZzZrWXlRMGl4RkhUeXlic2lMLTNhMlEwNHNncXBDandiWXVjYkN1MklYbk1IMUdyUkFSRnRMcUQ2ZVNzQWhFN01veHBDRkRZTXdiNEtPUnAwc2o2T2JSUTB3Q0E?oc=5", "content": "삼성 \\"귀걸이·목걸이 등 AI 웨어러블 확대 적극 검토 중\\" - AI타임스"}, {"url": "https://news.google.com/rss/articles/CBMiVkFVX3lxTFBZNGJseTNwX1hUbnpCREEzV1kxd1NHUTJUMUp4SHUxWFRHcFBDcG1IbGZXdExfQWstc1QzTDVhdzFwTF94MDY2QTR2MG13Z0xlZEdVOTZn0gFXQVVfeXFMUEtzb3pES1FldnY4dmVFaW5uZExHc1U3U3NyQjJzaUgtOHJyR3JMNURUdk5qbk9zZkFPTUIyaTJ0UUlmNm8xbmxXNEdIOC1uYzUxSEFTbVdF?oc=5", "content": "[단독] 삼성, \'딥시크 AI\'로 반도체 사업 혁신 나선다 - 서울경제"}, {"url": "https://news.google.com/rss/articles/CBMiZkFVX3lxTFBlUmpMamE3bzl2RjlGX2xOSUpYSGhHWlBNX3lBZ1hwVHJCdHRqeC1ObHI1S3NheUZpaXQ1aWptU1RjQTkxUlhLbmhoSGhsVWw5NWloQWUzVkVhUnRXYjZrang1WVh4Z9IBbkFVX3lxTFBabmRxSXVFT3UtVWZvSG1JcC1yZVZFZlhtYXA0OFoyNk90d1RTajc4SlFtQ3Y0NE9pbjB3RC1BVjdGNEpzX2t6UFlYVzdEWkFVZURqRjVCLWMwTjEyQ2FjZFMtMllJOFpKTXdiNXJB?oc=5", "content": "\\"우산 챙겨\\" \\"댕댕이 자는 중\\" 먼저 말 걸며 술술…눈치 100단 삼성 AI - 머니투데이"}]', name='googlenews_search_tool', id='3d4e6be5-7aef-4bd6-a606-35f7c7edc8b2', tool_call_id='x5dfrvj4m')]}
# Step Output: {'messages': [HumanMessage(content='오늘의 AI 뉴스 알려줘.', additional_kwargs={}, response_metadata={}, id='b6e54454-d9b2-420e-b1aa-c4bc98b0a521'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'x5dfrvj4m', 'function': {'arguments': '{"query":"AI 뉴스"}', 'name': 'googlenews_search_tool'}, 'type': 'function', 'index': 0}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 973, 'total_tokens': 1000, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_c527aa4474', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--dbf0ee85-4c67-454e-add8-af66bc38ae2f-0', tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI 뉴스'}, 'id': 'x5dfrvj4m', 'type': 'tool_call'}], usage_metadata={'input_tokens': 973, 'output_tokens': 27, 'total_tokens': 1000, 'input_token_details': {}, 'output_token_details': {}}), ToolMessage(content='[{"url": "https://news.google.com/rss/articles/CBMiakFVX3lxTE9mYm1WUV9SZzZrWXlRMGl4RkhUeXlic2lMLTNhMlEwNHNncXBDandiWXVjYkN1MklYbk1IMUdyUkFSRnRMcUQ2ZVNzQWhFN01veHBDRkRZTXdiNEtPUnAwc2o2T2JSUTB3Q0E?oc=5", "content": "삼성 \\"귀걸이·목걸이 등 AI 웨어러블 확대 적극 검토 중\\" - AI타임스"}, {"url": "https://news.google.com/rss/articles/CBMiVkFVX3lxTFBZNGJseTNwX1hUbnpCREEzV1kxd1NHUTJUMUp4SHUxWFRHcFBDcG1IbGZXdExfQWstc1QzTDVhdzFwTF94MDY2QTR2MG13Z0xlZEdVOTZn0gFXQVVfeXFMUEtzb3pES1FldnY4dmVFaW5uZExHc1U3U3NyQjJzaUgtOHJyR3JMNURUdk5qbk9zZkFPTUIyaTJ0UUlmNm8xbmxXNEdIOC1uYzUxSEFTbVdF?oc=5", "content": "[단독] 삼성, \'딥시크 AI\'로 반도체 사업 혁신 나선다 - 서울경제"}, {"url": "https://news.google.com/rss/articles/CBMiZkFVX3lxTFBlUmpMamE3bzl2RjlGX2xOSUpYSGhHWlBNX3lBZ1hwVHJCdHRqeC1ObHI1S3NheUZpaXQ1aWptU1RjQTkxUlhLbmhoSGhsVWw5NWloQWUzVkVhUnRXYjZrang1WVh4Z9IBbkFVX3lxTFBabmRxSXVFT3UtVWZvSG1JcC1yZVZFZlhtYXA0OFoyNk90d1RTajc4SlFtQ3Y0NE9pbjB3RC1BVjdGNEpzX2t6UFlYVzdEWkFVZURqRjVCLWMwTjEyQ2FjZFMtMllJOFpKTXdiNXJB?oc=5", "content": "\\"우산 챙겨\\" \\"댕댕이 자는 중\\" 먼저 말 걸며 술술…눈치 100단 삼성 AI - 머니투데이"}]', name='googlenews_search_tool', id='3d4e6be5-7aef-4bd6-a606-35f7c7edc8b2', tool_call_id='x5dfrvj4m'), AIMessage(content="## Today's AI News Headlines\n1. 삼성, AI 웨어러블 확대 검토 중 - AI타임스\n2. 삼성, '딥시크 AI'로 반도체 사업 혁신 - 서울경제\n3. 삼성 AI, 대화형 서비스 강화 - 머니투데이", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 57, 'prompt_tokens': 1617, 'total_tokens': 1674, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_c527aa4474', 'finish_reason': 'stop', 'logprobs': None}, id='run--9880a013-a0cc-40de-893f-ab50ed58a1ab-0', usage_metadata={'input_tokens': 1617, 'output_tokens': 57, 'total_tokens': 1674, 'input_token_details': {}, 'output_token_details': {}})]}
"""
update: Adictthat streams updates to the graph, meaning changes to the graph state after each node execution.
1
2
3
4
5
6
7
8
for step in llm_app.stream(inputs, config, stream_mode="updates"):
print(f"Step Output: {step}")
"""
# Step Output: {'MyLLM': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'jtatg82qd', 'function': {'arguments': '{"query":"AI 뉴스"}', 'name': 'googlenews_search_tool'}, 'type': 'function', 'index': 0}], 'refusal': Non}, response_metadata={'token_usage': {'completion_tokens': 27, 'prompt_tokens': 973, 'total_tokens': 1000, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_c527aa4474', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--5cc3bc2d-3505-489a-9324-d41097fcfdcf-0', tool_calls=[{'name': 'googlenews_search_tool', 'args': {'query': 'AI 뉴스'}, 'id': 'jtatg82qd', 'type': 'tool_call'}], usage_metadata={'input_tokens': 973, 'output_tokens': 27, 'total_tokens': 1000, 'input_token_details': {}, 'output_token_details': {}})]}}
# Step Output: {'tools': {'messages': [ToolMessage(content='[{"url": "https://news.google.com/rss/articles/CBMiakFVX3lxTE9mYm1WUV9SZzZrWXlRMGl4RkhUeXlic2lMLTNhMlEwNHNncXBDandiWXVjYkN1MklYbk1IMUdyUkFSRnRMcUQ2ZVNzQWhFN01veHBDRkRZTXdiNEtPUnAwc2o2T2JSUTB3Q0E?oc=5", "content": "삼성 \\"귀걸이·목걸이 등 AI 웨어러블 확대 적극 검토 중\\" - AI타임스"}, {"url": "https://news.google.com/rss/articles/CBMiVkFVX3lxTFBZNGJseTNwX1hUbnpCREEzV1kxd1NHUTJUMUp4SHUxWFRHcFBDcG1IbGZXdExfQWstc1QzTDVhdzFwTF94MDY2QTR2MG13Z0xlZEdVOTZn0gFXQVVfeXFMUEtzb3pES1FldnY4dmVFaW5uZExHc1U3U3NyQjJzaUgtOHJyR3JMNURUdk5qbk9zZkFPTUIyaTJ0UUlmNm8xbmxXNEdIOC1uYzUxSEFTbVdF?oc=5", "content": "[단독] 삼성, \'딥시크 AI\'로 반도체 사업 혁신 나선다 - 서울경제"}, {"url": "https://news.google.com/rss/articles/CBMiZkFVX3lxTFBlUmpMamE3bzl2RjlGX2xOSUpYSGhHWlBNX3lBZ1hwVHJCdHRqeC1ObHI1S3NheUZpaXQ1aWptU1RjQTkxUlhLbmhoSGhsVWw5NWloQWUzVkVhUnRXYjZrang1WVh4Z9IBbkFVX3lxTFBabmRxSXVFT3UtVWZvSG1JcC1yZVZFZlhtYXA0OFoyNk90d1RTajc4SlFtQ3Y0NE9pbjB3RC1BVjdGNEpzX2t6UFlYVzdEWkFVZURqRjVCLWMwTjEyQ2FjZFMtMllJOFpKTXdiNXJB?oc=5", "content": "\\"우산 챙겨\\" \\"댕댕이 자는 중\\" 먼저 말 걸며 술술…눈치 100단 삼성 AI - 머니투데이"}]', name='googlenews_search_tool', id='7b1661fb-e5c6-40e2-b0f6-704bdb0d21cd', tool_call_id='jtatg82qd')]}}
# Step Output: {'MyLLM': {'messages': [AIMessage(content="## Today's AI News\n1. 삼성은 AI 웨어러블 기기 확대를 검토 중입니다. (출처: AI타임스)\n2. 삼성은 '딥시크 AI'로 반도체 사업 혁신을 추진하고 있습니다. (출처: 서울경제)\n3. 삼성의 AI 기술이 다양한 일상생활에서 활용되고 있습니다. (출처: 머니투데이)", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 81, 'prompt_tokens': 1617, 'total_tokens': 1698, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': 'fp_c527aa4474', 'finish_reason': 'stop', 'logprobs': None}, id='run--9a90bf45-65ca-40ef-86e3-4ae0303fa350-0', usage_metadata={'input_tokens': 1617, 'output_tokens': 81, 'total_tokens': 1698, 'input_token_details': {}, 'output_token_details': {}})]}}
"""
stream_mode=”messages”
- In the case of
stream_mode="messages":- You can output only the messages emitted from a specific node using
metadata["langgraph_node"].
- You can output only the messages emitted from a specific node using
- (Example) To output only the messages from the chatbot node:
metadata["langgraph_node"] == "chatbot"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
for chunk_msg, metadata in llm_app.stream(inputs, config, stream_mode="messages"):
if metadata["langgraph_node"] == "MyLLM":
print(chunk_msg.content, end="", flush=True)
1
최근 AI 뉴스로는 오픈AI의 내부 모습을 밝힌 퇴사자의 인터뷰, 오픈AI 출신 인물들이 주도하는 새로운 AI 산업의 발전, 그리고 오픈AI의 새로운 결제 시스템 개발 소식이 있습니다. 자세한 내용은 관련 기사를 참고하시기 바랍니다.
stream_mode=”values”
The values mode outputs the current state values at each step.
step.items()
key: The key of the statevalue: The value corresponding to the state key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
for step in llm_app.stream(inputs, config, stream_mode="values"):
for key, value in step.items():
print(f"\n[ {key} ]")
value[-1].pretty_print()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
[ messages ]
================================ Human Message =================================
오늘의 AI 뉴스 알려줘.
[ messages ]
================================== Ai Message ==================================
Tool Calls:
googlenews_search_tool (chatcmpl-tool-ec90e142c0044ddcbea50dc240d1a84a)
Call ID: chatcmpl-tool-ec90e142c0044ddcbea50dc240d1a84a
Args:
query: 오늘 AI 뉴스
[ messages ]
================================= Tool Message =================================
Name: googlenews_search_tool
- AI 날개 단 TSMC, 오늘 2분기 실적 발표…관전 포인트는? - 네이트 뉴스
- [오늘의 DT인] “AI 시대 트래픽 대비하려면 LTE 뺀 5G 단독모드 전환 서둘러야” - 디지털타임스
- [AI 활용 기사] 오늘 전국 비 ... 수도권 일부 200mm 집중호우 - LG헬로비전
[ messages ]
================================== Ai Message ==================================
Today's AI news includes:
1. TSMC is set to announce its Q2 performance today, and the focus is on its AI-driven growth.
2. The importance of transitioning to 5G standalone mode to handle AI-era demands.
For more news, you can visit the following links:
- https://www.nate.com (TSMC news)
- https://www.dt.co.kr (5G transition news)
stream_mode=”updates”
The updates mode outputs only the updated state for each step.
- The output is a
dictionarywhere the key is the node name and the value is the updated result.
step.items()
key: The name of the nodevalue: The output at that node step (a dictionary containing multiple key-value pairs)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
question = "오늘의 AI 뉴스 알려줘."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
for step in llm_app.stream(inputs, config, stream_mode="updates"):
for key, value in step.items():
print(f"\n[ {key} ]")
value["messages"][-1].pretty_print()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[ MyLLM ]
================================== Ai Message ==================================
Tool Calls:
googlenews_search_tool (0ht37215y)
Call ID: 0ht37215y
Args:
query: AI 뉴스
[ tools ]
================================= Tool Message =================================
Name: googlenews_search_tool
[{"url": "https://news.google.com/rss/articles/CBMiakFVX3lxTE1EalUxcEYzTk5qU2JFYVZXaE43eWIzdHpFY1lJdjJxdFJ0enpaa2hONk9sNGsyaXFqTWZ1UmxuemNVbVM5cUYzV0o5S1RsRXplaC1lZWRwMEpEcjFJVldkbkNtb0RybnV6dlE?oc=5", "content": "LG, 하이브리드 AI ‘엑사원 4.0’ 공개...\"글로벌 프론티어 성능 도달\" - AI타임스"}, {"url": "https://news.google.com/rss/articles/CBMiW0FVX3lxTE14WHNrWXNaRl96VEU5aHZ4WGVVTlNqMjdrS01sZnNFMHZ1R0JzelJGUm5adTVMb0J5d2hhVzc5Xzgza2IyRmYxZ2ZHT3JxZGVhaV9zZVVLM2ZpV1HSAWBBVV95cUxOUmo1X2JTek5WZTBYcmhiblpYN1dMWGNHdUZsN0FHT1N5ZzlYTGJ6WGNxS2NlVVF0MW1jUWlfTEx3Q05CV3NCcnJ6M1hBYTg2cUc1Y2RHeW81MGptRFo2MmE?oc=5", "content": "코오롱베니트, LG 엑사원 기반 AI 관제 패키지 개발 - 연합뉴스"}, {"url": "https://news.google.com/rss/articles/CBMiZ0FVX3lxTE1RekNHNmh6Q3VoeHA1YXRRTEkxeXpqT0ZlbGtoMDFnQk5HTm1WSTVSUTRrbW05cWZNamVyUGRUeXI5WTdqSlZEUnY5Yzk5ME5XRzVhaWN4Q2wwMHNTYlN5TWVJcVJIVVk?oc=5", "content": "코오롱베니트, 인공지능 안전 관제 시스템 ‘AI 비전 인텔리전스’ 발표 - 인공지능신문"}]
[ MyLLM ]
================================== Ai Message ==================================
LG가 하이브리드 AI '엑사원4.0'을 공개했으며, 코오롱베니트는 LG 엑사원 기반 AI 관제 패키지를 개발했습니다. 또한 코오롱베니트는 인공지능 안전 관제 시스템 'AI 비전 인텔리전스'를 발표했습니다.
Memory evaluation
LangGraph internally uses the concept of an execution “thread” to distinguish between different states. In the code below, "thread_id": 11 can be considered a unique session ID for a multi-turn conversation. Based on this value, a checkpointer like SqliteSaver stores and retrieves the conversation state.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": 11})
question = "내이름은 DS2Man이야."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
result = llm_app.invoke(inputs, config)
print("====" * 4)
print(f"Total number of messages: {len(result['messages'])}")
print("====" * 4)
print("All messages:")
for idx in range(len(result['messages'])):
print(f"{result['messages'][idx]}")
print("====" * 4)
print(f"Final response:\n{result['messages'][-1].content}")
print("====" * 4)
1
2
3
4
5
6
7
8
9
10
================
Total number of messages: 2
================
All messages:
content='내이름은 DS2Man이야.' additional_kwargs={} response_metadata={} id='88cc0f81-74e8-443c-a9e5-15a49140e64c'
content='반가워, DS2Man! 만나서 반가워. 혹시 도와줄 일 있어?' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 22, 'prompt_tokens': 774, 'total_tokens': 796, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run--9d12a2a4-db6c-4d0d-9a1c-b00ba5c46e7b-0' usage_metadata={'input_tokens': 774, 'output_tokens': 22, 'total_tokens': 796, 'input_token_details': {}, 'output_token_details': {}}
================
Final response:
반가워, DS2Man! 만나서 반가워. 혹시 도와줄 일 있어?
================
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": 11})
question = "내이름은 DS2Man이야."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
result = llm_app.invoke(inputs, config)
print("====" * 4)
print(f"Total number of messages: {len(result['messages'])}")
print("====" * 4)
print("All messages:")
for idx in range(len(result['messages'])):
print(f"{result['messages'][idx]}")
print("====" * 4)
print(f"Final response:\n{result['messages'][-1].content}")
print("====" * 4)
1
2
3
4
5
6
7
8
9
10
11
12
================
Total number of messages: 4
================
All messages:
content='내이름은 DS2Man이야.' additional_kwargs={} response_metadata={} id='06f72acf-75f5-486a-84cd-e1a61d00463e'
content='반가워요, DS2Man! 무엇을 도와드릴까요?' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 1251, 'total_tokens': 1267, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run--4ad8c86e-0151-4304-8cf0-ab439a61e29f-0' usage_metadata={'input_tokens': 1251, 'output_tokens': 16, 'total_tokens': 1267, 'input_token_details': {}, 'output_token_details': {}}
content='내이름이 뭐라고?' additional_kwargs={} response_metadata={} id='5cbf6732-9531-442a-9896-9afea49bc475'
content='당신의 이름은 DS2Man입니다.' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 783, 'total_tokens': 793, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run--ac2c1a87-3faf-41d5-8eb0-4dc5c7cbd784-0' usage_metadata={'input_tokens': 783, 'output_tokens': 10, 'total_tokens': 793, 'input_token_details': {}, 'output_token_details': {}}
================
Final response:
당신의 이름은 DS2Man입니다.
================
Check saved state
1
2
3
# `get_state(config)`: Retrieves the current state of the execution object as a snapshot, based on the specified `config` (e.g., thread ID).
snapshot = llm_app.get_state(config)
snapshot.values["messages"]
1
2
3
4
[HumanMessage(content='내이름은 DS2Man이야.', additional_kwargs={}, response_metadata={}, id='06f72acf-75f5-486a-84cd-e1a61d00463e'),
AIMessage(content='반가워요, DS2Man! 무엇을 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 1251, 'total_tokens': 1267, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4ad8c86e-0151-4304-8cf0-ab439a61e29f-0', usage_metadata={'input_tokens': 1251, 'output_tokens': 16, 'total_tokens': 1267, 'input_token_details': {}, 'output_token_details': {}}),
HumanMessage(content='내이름이 뭐라고?', additional_kwargs={}, response_metadata={}, id='5cbf6732-9531-442a-9896-9afea49bc475'),
AIMessage(content='당신의 이름은 DS2Man입니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 783, 'total_tokens': 793, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--ac2c1a87-3faf-41d5-8eb0-4dc5c7cbd784-0', usage_metadata={'input_tokens': 783, 'output_tokens': 10, 'total_tokens': 793, 'input_token_details': {}, 'output_token_details': {}})]
1
2
3
4
5
6
# Configuration details
snapshot.config
# {'configurable': {'thread_id': '10',
# 'checkpoint_ns': '',
# 'checkpoint_id': '1f06a727-fc46-6614-8004-49892a8cff8c'}}
1
2
3
4
5
6
7
# Check the state values saved so far
snapshot.values
# {'messages': [HumanMessage(content='내이름은 DS2Man이야.', additional_kwargs={}, response_metadata={}, id='06f72acf-75f5-486a-84cd-e1a61d00463e'),
# AIMessage(content='반가워요, DS2Man! 무엇을 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 1251, 'total_tokens': 1267, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4ad8c86e-0151-4304-8cf0-ab439a61e29f-0', usage_metadata={'input_tokens': 1251, 'output_tokens': 16, 'total_tokens': 1267, 'input_token_details': {}, 'output_token_details': {}}),
# HumanMessage(content='내이름이 뭐라고?', additional_kwargs={}, response_metadata={}, id='5cbf6732-9531-442a-9896-9afea49bc475'),
# AIMessage(content='당신의 이름은 DS2Man입니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 783, 'total_tokens': 793, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--ac2c1a87-3faf-41d5-8eb0-4dc5c7cbd784-0', usage_metadata={'input_tokens': 783, 'output_tokens': 10, 'total_tokens': 793, 'input_token_details': {}, 'output_token_details': {}})]}
1
2
3
# Check the next node – since END has been reached, the next node is empty.
snapshot.next
# ()
Memory remove
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": "RemoveMessage1"})
question = "내이름은 DS2Man이야."
inputs = {
"messages": [
HumanMessage(
content=question
)
],
}
result = llm_app.invoke(inputs, config)
print("====" * 4)
print(f"Total number of messages: {len(result['messages'])}")
print("====" * 4)
print("All messages:")
for idx in range(len(result['messages'])):
print(f"{result['messages'][idx]}")
print("====" * 4)
print(f"Final response:\n{result['messages'][-1].content}")
print("====" * 4)
1
2
3
4
5
6
7
8
9
10
================
Total number of messages: 2
================
All messages:
content='내이름은 DS2Man이야.' additional_kwargs={} response_metadata={} id='88cc0f81-74e8-443c-a9e5-15a49140e64c'
content='반가워, DS2Man! 만나서 반가워. 혹시 도와줄 일 있어?' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 22, 'prompt_tokens': 774, 'total_tokens': 796, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run--9d12a2a4-db6c-4d0d-9a1c-b00ba5c46e7b-0' usage_metadata={'input_tokens': 774, 'output_tokens': 22, 'total_tokens': 796, 'input_token_details': {}, 'output_token_details': {}}
================
Final response:
반가워, DS2Man! 만나서 반가워. 혹시 도와줄 일 있어?
================
1
2
3
# `get_state(config)`: Retrieves the current state of the execution object as a snapshot, based on the specified `config` (e.g., thread ID).
snapshot = llm_app.get_state(config)
snapshot.values["messages"]
1
2
[HumanMessage(content='내이름은 DS2Man이야.', additional_kwargs={}, response_metadata={}, id='06f72acf-75f5-486a-84cd-e1a61d00463e'),
AIMessage(content='반가워요, DS2Man! 무엇을 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 1251, 'total_tokens': 1267, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4ad8c86e-0151-4304-8cf0-ab439a61e29f-0', usage_metadata={'input_tokens': 1251, 'output_tokens': 16, 'total_tokens': 1267, 'input_token_details': {}, 'output_token_details': {}})]
1
2
3
4
5
6
# 메시지 배열의 첫 번째 메시지를 ID 기반으로 제거하고 앱 상태 업데이트
llm_app.update_state(config, {"messages": RemoveMessage(id=messages[0].id)})
# {'configurable': {'thread_id': 'RemoveMessage1',
# 'checkpoint_ns': '',
# 'checkpoint_id': '1f0621a4-8785-67f2-8002-d4033576af7e'}}
1
2
snapshot = llm_app.get_state(config)
snapshot.values["messages"]
1
[AIMessage(content='반가워요, DS2Man! 무엇을 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 1251, 'total_tokens': 1267, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'meta-llama/llama-4-maverick', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4ad8c86e-0151-4304-8cf0-ab439a61e29f-0', usage_metadata={'input_tokens': 1251, 'output_tokens': 16, 'total_tokens': 1267, 'input_token_details': {}, 'output_token_details': {}})]